
 广东
广东
在 OpenAI 融资完之后,Perplexity 也在找钱了:据《华尔街日报》报道,这家一直以来广受好评的 AI 搜索,希望以 80 亿美元的估值,寻求 5 亿美元的融资。

虽然自从出道以来,Perplexity 在搜索上一直很领先,但不是没有与各大出版商闹矛盾,而且也不是没有对手,各家都对搜索业务,都盯得很牢。
真正落实到使用层面,总有一个问题:被 AI 赋能,尤其是被大语言模型赋能之后的搜索,究竟哪里有所不同了?
这篇文章里我们测评了几个推出了「大升级」了的 搜索 工具, 包括 Perplexity 的 Pro 模式,GPT 的新模型、 Kimi 的探索版, 智谱的 AI 搜索,秘塔 的深度和研究版 。
简而言之:更广更多的资料、更深的信息占有量,是毋庸置疑的,但这只是一部分。还可以更有所不同的,是对用户意图的理解与感知。
关注 AI 第一新媒体,率先获取 AI 前沿资讯和洞察
实用性测评:不仅能搜,搜完就能用
如果说 AI 加持后的搜索功能有什么变化,一定是实用性上的提升,得到的信息对解决实际问题更有效了。
以一个操作性非常强的问题为例,「如何在 mac 系统上,批量修改音乐文件封面」。
在百度这样的传统搜索引擎上,输入关键字,出现的是一大堆信息的罗列,而且关联度很低。

Google 的关联度好一点,但还是需要用户自己点进去,逐一确认内文究竟说的方法,是不是能用。

从前的搜索引擎,是围绕关键字,搜罗一大堆信息,有相似度,但不多,并且需要用户自己做第一轮整理。
而大语言模型给搜索注入灵魂之后,重新组织了海量信息,整合成了相关度最高的样子,返送给用户——这直接省掉了第一轮整理的过程。比如下面的 ChatGPT,根据方法的类型,总结出了三类。

不过,AI 虽好但不能依赖,比如下面智谱,在「使用 Finder」和「使用 Apple Music」两个方式下面的细节步骤,完全是一样的。

更保险的方法是在几个 AI 搜索里,同一个问题获取不同的回答,横向对比,以免其中一个出现幻觉。
接下来,在操作细节上进一步询问,也会提出相应的方法。

Kimi 探索版

相比于 4o 给出的笼统回答,Kimi 给出了更多的细节——或者说,是在 4o 的基础上,调整了回答的格式,让回答更有操作性。
不是每个 AI 搜索都擅长给具体实用的建议,像 Perplexity,就只丢出来可以用的软件。

实用性还体现在对数据的抓取上,以 Kimi 的演示 prompt 为例「世界上最有钱的 10 个人是谁?他们都是做什么的?」,各家的表现都不太一样。

其中,注重资料深度的 Perplexity 和 Kimi,都把具体的数字列出来了,Perplexity 更加是直接拉了个表格,每一个词条都贴出了出处。

涉及到数字的信息,列表格是更清晰的方式。不过 Perplexity 自己的表格,和下面的总结里,排序不太一样。甚至,这四个 AI 搜索给出的结果排序,都不太一样——自行核查还是很有必要的。
接下来我尝试了一个比较有挑战性的问题,「在准备业余无线电考试期间,我可以买什么样的设备熟悉操作?」
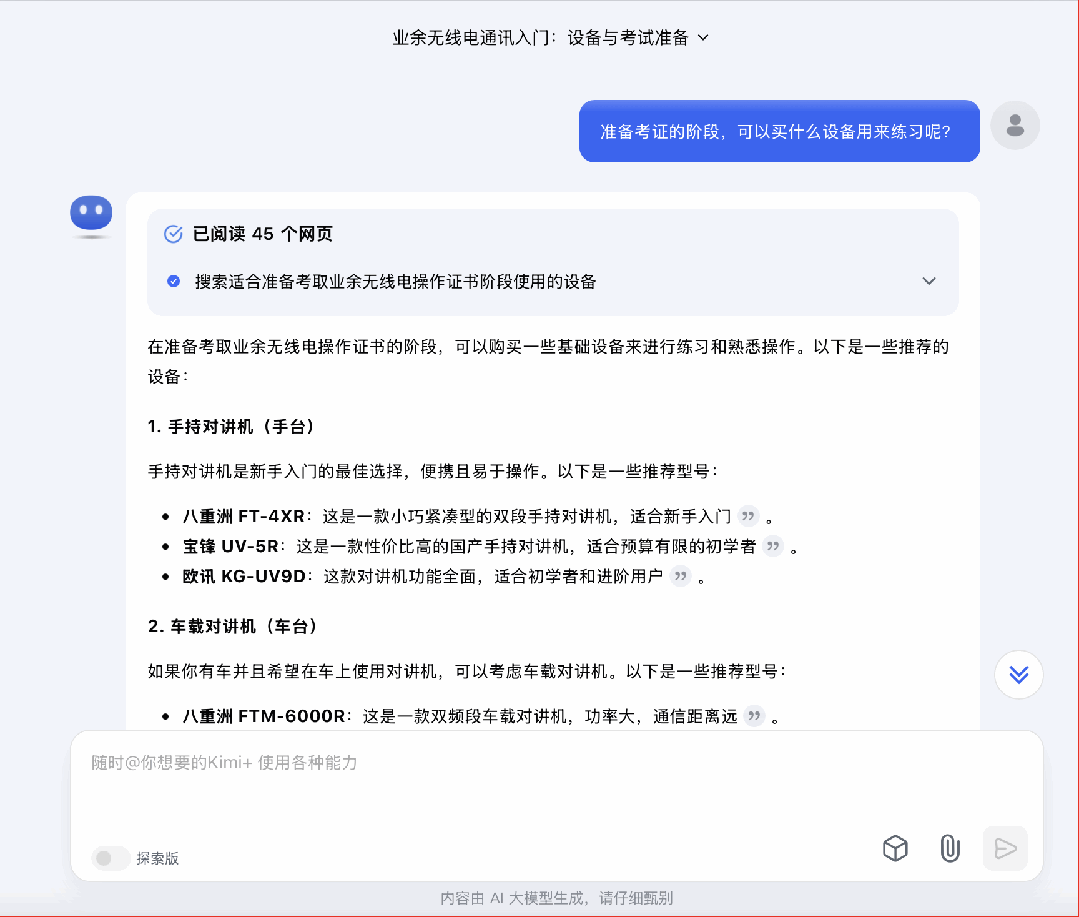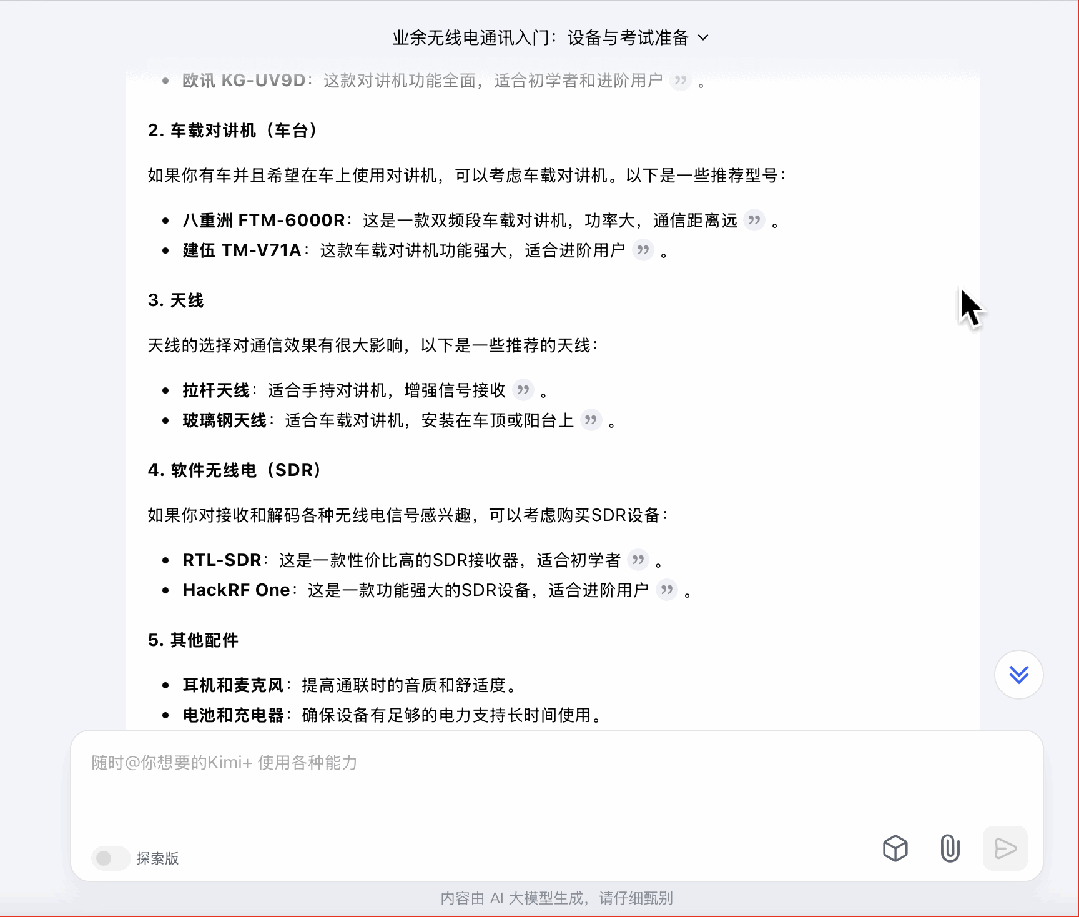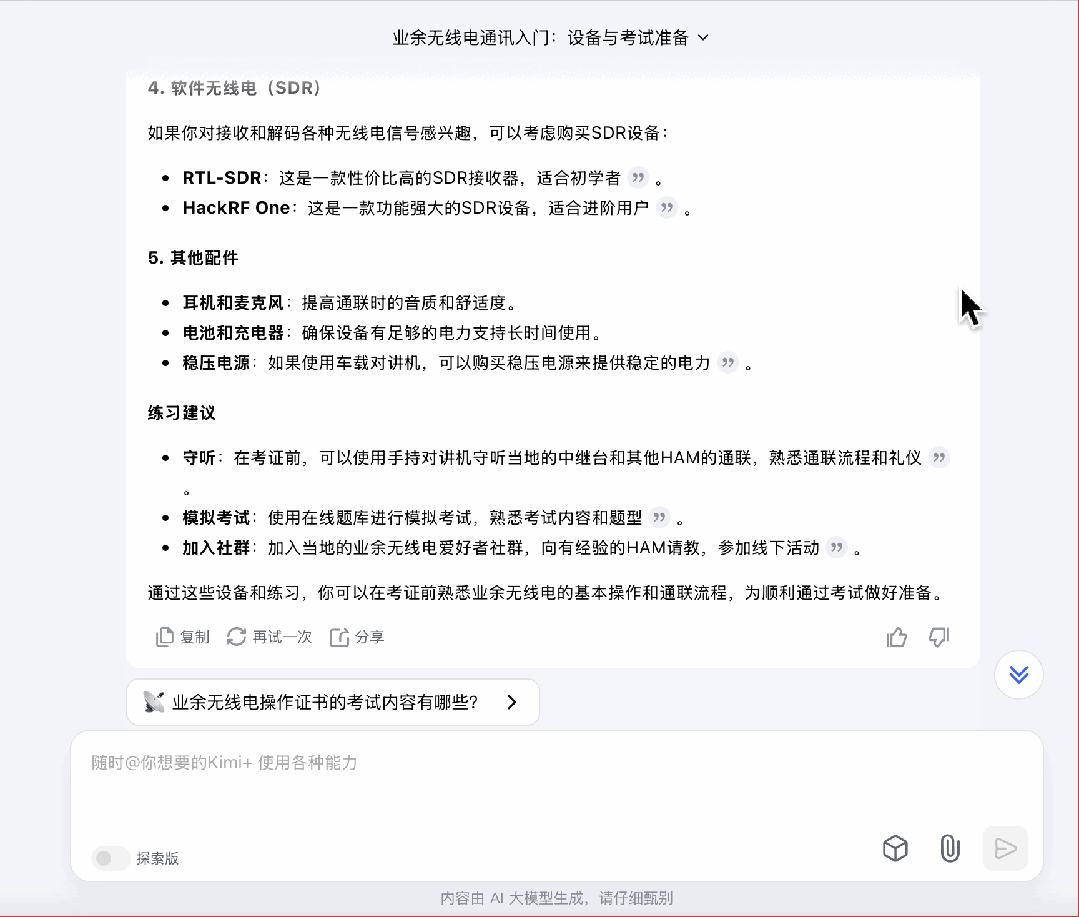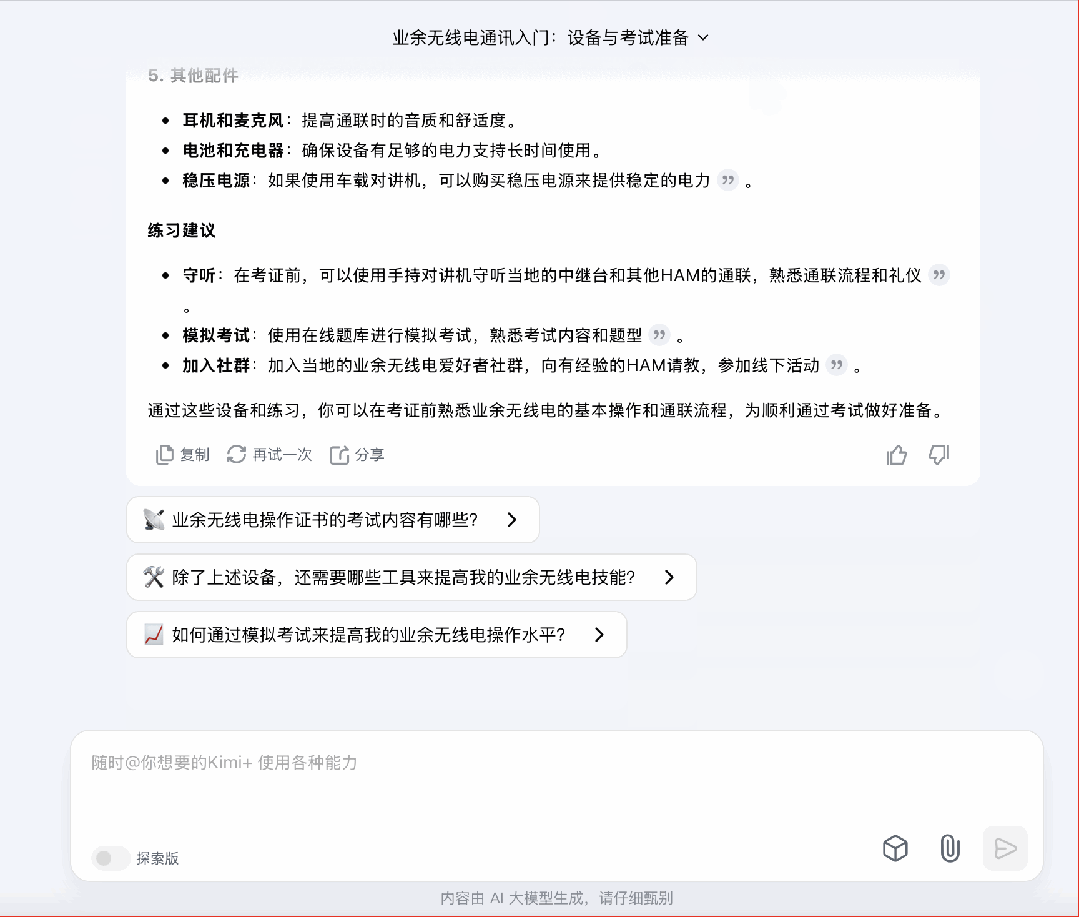
一个小小的备注:业余无线电是需要考证的,在牌照下来前,只能听不能发。所以这个问题,暗地里在考验模型会不会了解到这样的「隐藏信息」。
秘塔和 Kimi 都直接给出了设备的种类、建议的品牌。其中秘塔还从一些论坛里搜索,整合出了用户评价。这个做法沿可以扩展到所有比价的场景上。

不过,这几个 AI 搜索都没有涉及到是否具备发射资格的问题,秘塔和智谱提到了要确认设备是否具备发射核准,但这是针对设备而不是用户的。Kimi 模糊地提到需要遵守通联流程和礼仪,比较像是按惯例写了点安全守则。

「在准备考试期间」已经非常明牌了,这就是还没有取得牌照的阶段。只能说 AI 在真正理解用户的处境这方面,还是能力有限。
简单小结一下是:基于大模型的 AI 搜索更有实用性,能够整合海量信息,提炼出最有效的部分。
资料深度:是搜索就下一百层
在测评实用性的过程中,我发现 Kimi 随机提供的一些演示案例里有这样一个问题:标注三国战役地点,对应现代城市和地区。
很自信喔。
三国是中国历史上非常有趣的一个历史时期,群雄割据,人物和事件多变。而且正史和野史齐飞,三国演义和三国志傻傻分不清。
更有趣的是,在中文以外的世界也有很多研究对三国感兴趣,欧美和日本有不少针对汉代和三国的研究学者,是一个信息存量很丰富的时期。
这样一个问题,就非常考验对资料和信息的占有量。
这一次我直接把 ChatGPT 踢出战局了,因为不提供具体出处,没办法判断它的占有深度。我决定用主打文库检索的秘塔代替它的位置。

可以看到中间 Perplexity 和智谱,表现无功无过,都以官渡之战作为三国的开端来计算,周期大概是公元 200 年到 230 年之间。
而 Kimi 展现出了一些不同的理解:以公元 184 年的黄巾起义为开端,把后汉末尾、三国前夜的几场战事都包含了进去。我问了一下为什么这么做,它回答:我不是,我没有。

而秘塔搜索展示出了完全不一样的资料占有量。就像上面说,在文库和深入模式下,它不仅有相关教科书上的研究,囊括了非中文的相关文献。

可能是时效性还可以提高,这两年出版的一些新书没有囊括进去。但是这个资料占有量的广度和丰富度,已经相当不错了。
不过秘塔有一个迷惑的 bug:居然翻查了 Kimi 的测评网页……

AI 生成 AI 搜,闭环了属于是。
这个 bug 反而能看出来,AI 搜索再先进,也会有无效网页,本质上还是基于对 prompt 更细的拆解,切分出更小单位的关键词——至于有没有后探到关键词所属的知识领域,那就不一定了。
这是中文资料的检索。接下来我做了另一个检索,更偏向于非中文资料:1978 年,哲学与心理学协会举办了一场座谈会,最后这演变成了几位哲学家对于 AI 的辩论,其中包括诺姆·乔姆斯基(Noam Chomsky)、杰里·福多(Jerry Fodor)、罗杰·尚克(Roger Schank)和特沃·温诺格拉德(Terry Winograd)。具体的情况是什么?

四个搜索给出的回答都大同小异:整理了这场辩论的正反方人物、各自的观点、这场辩论所带来的影响,等等,算是打了个平手。
不过,考虑到这次主要看的是资料深度,秘塔的表现更好,资料深度很惊艳。

实际上,1978 年的这次辩论没有太多原始记录,只有哲学家 Daniel Dennett 的一篇论文中提到了一下。Perplexity 和 Kimi 都需要追问一下,智谱则是在追问环节直接卡住了。秘塔第一次就收录到了这篇论文,放在了引用目录里,点击可以直接找到相关的段落。

总结一下,大语言模型对于搜索而言最有意义的是两点:一,基于语义的用户理解,提供有操作性的信息。二,跳出关键字的圈圈,后探到更深的知识领域。
这两点说起来容易,做起来很难。两者当中,都涉及对用户意图的理解。
但是了解用户的意图,难度堪比读空气——打过工的人都知道,这里面的门道有多深。不要说模型对人的意图理解,就是日常生活中人与人之间、同事与同事之间、同事与领导之间,想要理解彼此的意图,都要付出沟通成本。
模型想要通过用户的提问来揣测意图,前提是提问越清晰越好,然而用户自己可能也并不百分百清楚自己要的是什么。
相比之下,后者的容错率更高一点:不知道用户到底想要什么,那就有什么给什么,资料深度直下一百层,总有一份能击中目标。这可能也是为什么各家 AI 搜索,在推出 Pro 版、plus 版、深度版等等高级服务时,都主打一个搜索又大又全。
而这场竞争的下一个赛点,可能恰恰在前者,毕竟那涉及到人类对人工智能的终极幻想:想我所想,懂我所懂。


特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
Notice: The content above (including the pictures and videos if any) is uploaded and posted by a user of NetEase Hao, which is a social media platform and only provides information storage services.






































































